
软件工具
HBuilderX gem brew 会员管理系统 iopaint yaml Rider Auto GPT Airtest Stable Diffusion 飞书 Programmer AI Copilot X softwares for windows softwares for mac softwares for ios softwares for android Filezilla Cocoapods wireshark pyCharm Microsoft Edge vscode 短信关键字 Ubuntu 阿里云 视频下载 百度贴吧 百度云管家 爬虫 模拟器与手机 晨风QQ机器人 文件下载 按键精灵 抖音 微信 京东 云手机 yarn virtualbox vim truffle tor browser tomcat telegram sqlite3 spine shell shadowsocks scrapy scons rust repo pyenv preact pp助手 phpstorm pgAdmin pear pecl parity nvm npm nginx markdown magnet loadrunner laravel jekyll itunes iPhone heroku govendor google chrome gitlab github git eclipse docker cygwin composer cocos studio cmake carthage batch command apktool apachectl apache adobe photoshop adb aapt ZeroNet Xcode Windows WinHex WebStorm Visual Studio VMware TortoiseSVN ThinkSNS TexturePacker TeamViewer Subversion Sublime Text SourceTree SecureCRT SVN RTX QQ PostgreSQL OpenIM OpenGL Shader Builder OD Notepadplusplus Navicat for MySQL Mono MongoDB MinIO MinGW Microsoft Visual Studio Mac OS X Linux Laradock Kafka Jenkins Genymotion FontCreator ETCD CocosBuilder CentOS Bootstrap Beyond Compare Angular2 Android Studio 3ds Max 360 Visual Studio2010快捷键及设置 ChatGPT HRESULT 0x80004005 E_FAIL 美团开店宝 搜狗输入法 ohmyzsh meson golang mobile library gitea flutter多版本管理工具 - fvm _ WireGuard V2Ray RocketChat Fork Clash Advanced Installer Siliconflow ollama _ Google Colab DeepSeek ChatGPT局限性研究 AnythingLLM编程开发
Unity 团结 雷电模拟器闪退 微赞 golang在docker中运行 Open Source for Flutter Open Source for Android Android渲染 Unity UIWidgets Open Source for Unity Unity超链接 Unity spine Unity shader lua热重载 Bloom chrome extension Particle System Sprite Renderer Overdraw 字体描边 Unity热门插件 TronLink Bmfont TextMeshPro Behaviour Tree ThinkPHP ajax Hexagonal Grids python基础知识 python argparse和optparse eth eth layer2 ios点滴积累 exr UGUI优化 lua定义不允许定义变量的class 7za源码 打印堆栈 C C++点滴积累 android基础知识 xLua java基础知识 Unity DOTS Unity大规模角色渲染 Flutter metamask andriod源码编译 React Native git as a database android逆向 越狱 ios逆向开发 ipfs链编程 cocos2d-x3.x文字模糊 lua创建class v3quick 智能合约升级方案 gitlab服务器迁移 go调用C++ 区块链编程 cocos2dx lua项目转html5项目 SSL aar转jar Unity热更方案 Unity 升级 源码 反编译获取任何微信小程序源码 基础知识 cocos2dx ipv6支持 ClippingNode sprite的触摸事件 redis 加密算法 protobuf JAR creation failed. See details for additional information cocos2dx内存管理 SDK服务器 vpn服务器搭建 获取焦点 某些android系统下自动优化代码 异常处理 内存泄露分析 代码混淆 生成唯一id oauth2 IIS和tomcat共用80端口 enum MultiValueMap 易语言基础知识 MySQL eclipse的devices上不显示调试程序包名 搭建服务器下载文件 switch case的效率问题 获取版本号和版本名 cocos2d-js js语法 meta-data的获取 cocos2d-js安装 Paper2D rapidjson unreal源码赏析 NEON reload lua scripts go发邮件 smali语法 Spring lua枚举实现 PainTown编译 STL各容器操作 ios性能测试 UI Engines Game Engines Comparison CCActionInterval cocos bugs variadic templates singleton class POSIX g3log 不能在非主线程中使用OpenGL ES的UI函数 Menu get class name based on class #type 宏的含义 类模板的部分特化 各编译器对C++的支持度 Open Source Log Systems Comparison 百度语音识别SDK 锚点anchorPoint Unity插件 View Frustum Culling Matrix Layouts, DirectX and OpenGL DirectX基础知识 详解Cocos2d-X中宏CC_DLL android 国际化语言 locale缩写 android error solutions Unity调用webservice Unity调用C++的dll Unity Error Solutions 非组合BCD码VS组合BCD码 磁盘的磁道(track) use static Variables in static library ndk编译出错-Werror UNICODE字符集之 UTF-8、UTF-16 SpringBoard 无法启动应用程序 -4 Setting up a Code Repository on Google 透视投影变换 编译ogre_src_v1-7-4 windows 编译 ogre 1.9.0 ios undo 绘制次序 纹理寻址模式设置不当 显存带宽 bandwidth 分析碰撞检测库Opcode 《Fighting, Antiquity》遇见的各种问题 send TEXCOORD from DirectX9.0 to HLSL mul(inPos, matViewProjection) and mul(matViewProjection, inPos) A* Pathfinding X File Hierarchy Loading VS高亮HLSL关键字 Umbra 3:次世代的遮挡裁剪 Steering Behaviors For Autonomous Charac Rendering the Great Outdoors/Fast Occlusion Culling for Outdoor Environments Programming OpenGL ES with ios Perlin Noise OpenGL中freeglut的安装 OpenGL OpenGL ES hardware support OgreSDK_vc10_v1-7-4第一次编译程序运行crash Missing texture object named 'Texture0' in pixel shader 'Pixel Shader' in pass 'Pass 1' Loading .x files the easy way Load .obj model Get Texture Coordinates from DirectX in Vertex Shader Fx Composer Effect Framework DirectX 9.0中BeginPass和EndPass放置问题 DirectInput Coding in RenderMonkey Bézier curve Bullet Advanced Collision Detection Techniques 3D游戏引擎中的室外大场景渲染技术研究与实现 3D实时渲染中的BSP树和多边形剔除 fxc的使用及调试技巧 编译注意点 点滴积累 windows搭建android和cocos2dx环境 sprite::create("*.png")崩溃 Unknown EABI object attribute 44 CCUserDefault使用注意点 APP_STL := gnustl_static APP_CPPFLAGS := -frtti APP_CPPFLAGS += -fexceptions #pragma once与 #ifndef的区别 #ifdef _DEBUG 重载识别多重继承 返回值尽量返回const值 缺省实参编译时刻决定 编译器优化 纯虚析构函数必须定义 类继承中调用函数 类模板运用之实现委托类 类模板运用 类模板的友元 类成员函数声明为另外一个类的友元 析构函数出域就析构 指针的运用 成员函数模板和自动转换的选择 成员函数指针的运用 成员函数和非成员函数重载问题 在if里面请写入语句 使得打印出 hello world。 typedef作用 —— 定义机器无关的类型 static_cast注意点 static DWORD成员变量定义 operator<<重载 multimap容器不能用greater_equal case语句内定义变量 boost使用 本地函数定义是非法的 __attribute__ Type Conversion Override controls override and final OSI七层网络模型与TCP:IP四层网络模型 C:C++里面变量名的最大长度是多少? C++模板初始化 .h和.hpp区别 游戏崩溃查找dump crash堆栈信息 未签名的apk无法安装到手机上 延迟执行任务 平台接入 安装apk到手机中,elipse并非完全拷贝整个apk 多线程用多少个线程最合适 使用NDK编译so动态库 中国移动第三方接入 onNewIntent eclipse调试android程序 eclipse下android环境搭建 apk重启程序代码 apk 签名 ant 自动编译 android开发中遇到sqlite3 not found android制作九宫格图 android.database.CursorIndexOutOfBoundsException android 指定类 android ndk 开发之Application.mk android assets常见问题 android 4.0 NetworkOnMainThreadException ZXing竖屏解决(完美版) XP环境下java环境变量配置 Unable to execute dex/Multiple dex files define The nested fileset element is deprectated, use a nested path instead Re-installation failed due to different application signatures. ROM修改 NDK工具之 addr2line NDK和Eclipse的集成 MySQL相关 ListView无法在onCreate的时候getChildCount() JNI运用 Database Design/UUID vs Integer Auto-Increment Android点滴积累 Android查看内存 Android.mk文件详解 Android string Android NDK 官方下载地址 Adding ActionBar Items From Within Your Fragments Activity 生命周期 php环境搭建 Objective-C的方法原型和重载 c#反射机制 .NET入门 mac 下搭建lua环境 objective c点滴积累 OGRE点滴积累 Unity点滴积累 Unity NGUI lua基础知识 golang基础知识 typescript基础知识 solidity基础知识 php基础知识 nodejs基础知识 kotlin基础知识 javascript基础知识 html基础知识 C#基础知识 css基础知识 破解技术 assembly点滴积累 _ _ Unity 模型 Unity 优化 Unity Webview Unity Odin Unity Editor HybridCLR _ _ _ _ uniapp meteor kodi gopeed generative_agents _ VLC Media Player MPV MLN ChatDev _ _ Copay _ _ gradle _ _ _ _errors
MacOS 升级BigSur后无法使用git svn Unit php-fpm.service could not be found Uncaught ReferenceError process is not defined Uncaught ReferenceError Buffer is not defined thread.cc Throwing new exception length=433 index=1340 ArrayIndexOutOfBoundsException Provisioning profile doesn't include signing certificate indenting spaces must be used in groups of 2 Nokogiri install failures eth合约报错 xcode __nwlog_err_simulate_crash_libsystem pod生成工程后编译lib The SSL certificate is invalid php编译错误 not a valid ELF invalid resource directory name appcompat_v7 res crunch Invalid Code Signing Entitlements 该文件没有与之关联的程序来执行该操作 dyld Library not loaded rpathlibfmodL a2003- cant connect to MYSQL server on localhost android.view.WindowManager BadTokenException is your activity running android.view.WindowLeaked no suitable device found no device found for connection git push Server error goroutine 1 efrror RPC failed result=18 HTTP code 200 This version of the rendering library is more recent than your err 1005 Can't create table error 150 could not initialize proxy no Session could not execute query nested exception ArtifactDescriptorException Failed to read artifact descriptor is not a valid JNI reference INSTALL_FAILED_DEXOPT brut.androlib.AndrolibException ARSCDecoder.decode error 未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0”提供程序 无法解析 __imp__printf 无法定位程序输入点sdl_strlcpy LNK1123: 转换到 COFF 期间失败: 文件无效或损坏 lwebsockets is not an object file Failed to git submodule update --recursive --init libpng error CgBI unhandled critical chunk symbol not found for architecture armv7 provider: 共享内存提供程序, error: 0 管道的另一端上无任何进程 and sa登陆失败 错误:18456 file is universal 3 slices but does not contain an armv7s slice error 126 无法解析的外部符号:error LNK2019 无法解析的外部符号 RegQueryValueEx、RegCloseKey、RegOpenKeyEx、RegSetValueEx... 无法解析外部符号 __imp__CoUninitialize@0、_TID_D3DRMFrameTransformMatrix 无法解析_c_dfDIMouse、_c_dfDIKeyboard、_DirectInput8Create@20、_c_dfDIJoystick2 无法解析 __imp__ExtractIconW@12、 __imp__ExtractIconW@12 无法打开文件"dxerr9.lib" 无法打开文件 d3dx9.lib 无法启动应用程序 1>------ 已启动生成: 项目: Init Direct3D, 配置: D 1>------ 已启动生成/项目/Font, 配置/Debug Win3 安装DirectXSDK时提示Error Code s1023 不允许使用不完整的类型 warning:DIRECTINPUT_VERSION undefined. Defaulting to version 0x0800 warning MSB8004: Output 目录未以斜杠结尾。此生成实例将添 warning C4996: 'strcpy': This function or variable may be unsafe. warning C4355: “this”: 用于基成员初始值设定项列表 warning C4290: 忽略 C++ 异常规范,但指示函数不是 __declspec(nothrow) warning C4003: “max”宏的实参不足 vs2010出现link2005 static_cast左右互搏
笔记本软件 Git Repositories Unity GUI 通讯协议 Open Source for nodejs Unity逆向工具 ps软件 NFT游戏 Open Source Audio 视频编辑软件 IM React Native Chat Library Messaging server backend go服务框架 浏览器 本地硬盘作服务器 自动按键 接码平台 数据清洗 go library for git go library for android ios React Native Apps Flutter Apps 加密算法 golang logging library python数据库框架 持续集成工具/Continuous integration(CI) 压缩存储 github guis git guis Gateway Server 图床工具 爬虫工具 lua远程调试器 去中心化数据库 去中心化云存储 noserver softwares php数据库框架 无服务器模式 服务器平台 宝塔 域名租用 php框架 文档管理工具 共识机制 库管理工具 区块链平台 量化交易 数字货币资讯软件 扩容方案 Web服务器 包管理工具 Web前端框架 交易所 Wallets DAPP Root工具 通用应用层协议 数据库 开发框架 数字货币 h5引擎 Open Source Cloud Disk 日志统计工具 博彩 团队协作工具 外包平台 ftp工具 remote control softwares log4j与slf4j 翻墙工具VPN scripting language low level graphics library Cygwin MinGW Build Tools 格斗引擎 shader tools UML Books 版本控制软件 Open Source Speech Recognition Physics Engines 远程控制软件 跨平台开发框架 自动测试工具 思维导图 序列化工具 工作流CI CD工具 局域网传输 uniapp开源框架 telegram server go library for server git in go app热更 _ PM常用工具 Optical Character Recognition(OCR) Open Source Video Player Open Source Shop Open Source Quantify Open Source Magnet Websites Open Source Chat点滴知识
日常 RPA 游戏工程设计细节 屏幕共享 AI Tool 工程规范 司法拍卖 第一性原理 数学 ecs 日语 科学锻炼记忆力 CPU缓存命中 OpenSea使用 apple store审核 博彩法律 BlockChain点滴积累 代扣支付平台 ios唯一标识 自制脱壳rom 自媒体 透明果实 飘三叶 斗牛 科幻 Fomo3D 区块链资源 googleplay支付 SSL证书安装 iPhone X全面屏适配 域名 SDK 生活 ipa重新打包 苹果过审 推广 王者荣耀 Pokemon GO 冒险与挖矿 Websites 规范 dnf地下城与勇士 实时对战手游 恐怖丛林肉搏 乱斗西游 专业常识 游戏开发书籍推荐 plist文件标识png图集的位置信息 mobile devices information 游戏设计书籍推荐 小说素材 正则表达式 Open Source Projects Daytoday Accumulation SEO 游戏同步 _数据结构与算法
背包问题 文件读取效率研究 随机选项和宽字符输出 过桥最短时间 输入一个正整数 设计一个程序 表达式求值 罗马数字与整数相互转换 编程求两个矩形的相交矩形 给定一个字串X 砝码称重 母函数问题 模拟实现乘法运算 某人有三个儿子 有一个长度为N的数字串 有5座不同颜色的房子 最长子串 最大子矩阵之和 在字符串S中寻找最 写一个程序 写一个函数 二维数组排序 一个线段随机分成三段能够构成三角形的概率 一个int数组,里面数据无任何限制,要求求出所有这样的数a[i], 其左边的数都小于等于它,右边的数都大于等于它。 能否只用一个额外数组和少量其它空间实现。 How many 0 appears Fabonacci数列定义为 Do remember 骆驼吃香蕉问题 错排原理 逻辑推理宴会握手 输入一个整数n 设计一个系统处理词语搭配问题 设计一个不能被继承的 设七位数是 编写代码把16进制表示的串转换为3进制表示的串 每个飞机只有一个油箱 概率问题 桌面上有24张光滑面扑克牌 根据上排给出十个数 有一个长度为998的数组 有一个复杂链表 有81个选手 有5个人比赛 有2.5亿个整数存放在一个文件中 有10个文件 无限容量的体育馆 数列L中有n个整数 把一个钝角三角形 循环队列 外星人打算将地球用来种蘑菇 在一天的24小时之中 判断另一字符串的所有字母是否在母串中都有 判断一个数是4的整数次幂 全部有火柴根组成 你有一个横6竖6的方格 九宫图解法 两个数组 不能使用库函数 下一个数是什么 一道小学数学题可以证明你是否可以玩股票 一个猜测游戏中 一个文件 一个教授逻辑学的教授 \[约瑟夫环\]n个数字 Longest Common Subsequence Fibonacci 12个高矮不同的人 100层楼 1000瓶药水 0-1背包 随机洗牌:哪种算法正确 求连续自然数平方和的公式 各种算法复杂度比较 教你如何迅速秒杀掉:99%的海量数据处理面试题 _ _undo
markdown usage todotodo
all todo标签
software 159
HBuilderX
gem
brew
会员管理系统
iopaint
yaml
Rider
Auto GPT
Airtest
Stable Diffusion
飞书
Programmer AI
Copilot X
softwares for windows
softwares for mac
softwares for ios
softwares for android
Filezilla
AI Tool
Cocoapods
wireshark
pyCharm
Microsoft Edge
vscode
短信关键字
Ubuntu
阿里云
视频下载
百度贴吧
百度云管家
爬虫
模拟器与手机
晨风QQ机器人
文件下载
按键精灵
抖音
微信
京东
云手机
yarn
virtualbox
vim
truffle
tor browser
tomcat
telegram
sqlite3
spine
shell
shadowsocks
scrapy
scons
rust
repo
pyenv
preact
pp助手
phpstorm
pgAdmin
pear pecl
parity
nvm
npm
nginx
markdown
magnet
loadrunner
laravel
jekyll
itunes
iPhone
heroku
govendor
google chrome
gitlab
github
git
eclipse
docker
cygwin
composer
cocos studio
cmake
carthage
batch command
apktool
apachectl
apache
adobe photoshop
adb
aapt
ZeroNet
Xcode
Windows
WinHex
WebStorm
Visual Studio
VMware
TortoiseSVN
ThinkSNS
TexturePacker
TeamViewer
Subversion
Sublime Text
SourceTree
SecureCRT
SVN
RTX
QQ
PostgreSQL
OpenIM
OpenGL Shader Builder
OD
Notepadplusplus
Navicat for MySQL
Mono
MinIO
MinGW
Microsoft Visual Studio
Mac OS X
Linux
Laradock
Jenkins
Genymotion
FontCreator
CocosBuilder
Beyond Compare
Angular2
Android Studio
3ds Max
360
ChatGPT
翻墙工具VPN
Cygwin MinGW
Build Tools
shader tools
UML Books
版本控制软件
美团开店宝
搜狗输入法
ohmyzsh
meson
golang mobile library
gitea
flutter多版本管理工具 - fvm
_
WireGuard
V2Ray
RocketChat
Fork
Clash
Advanced Installer
Siliconflow
ollama
_
Google Colab
DeepSeek
ChatGPT局限性研究
AnythingLLM
framework 14
android 64
雷电模拟器闪退
Open Source for Android
Android渲染
andriod源码编译
自制脱壳rom
aar转jar
JAR creation failed. See details for additional information
获取焦点
某些android系统下自动优化代码
异常处理
内存泄露分析
代码混淆
enum
MultiValueMap
eclipse的devices上不显示调试程序包名
获取版本号和版本名
js语法
meta-data的获取
smali语法
mobile devices information
android 国际化语言 locale缩写
android error solutions
游戏崩溃查找dump crash堆栈信息
未签名的apk无法安装到手机上
延迟执行任务
平台接入
安装apk到手机中,elipse并非完全拷贝整个apk
多线程用多少个线程最合适
使用NDK编译so动态库
中国移动第三方接入
onNewIntent
eclipse调试android程序
eclipse下android环境搭建
apk重启程序代码
apk 签名
ant 自动编译
android开发中遇到sqlite3 not found
android制作九宫格图
android.database.CursorIndexOutOfBoundsException
android 指定类
android ndk 开发之Application.mk
android assets常见问题
android 4.0 NetworkOnMainThreadException
ZXing竖屏解决(完美版)
XP环境下java环境变量配置
Unable to execute dex/Multiple dex files define
The nested fileset element is deprectated, use a nested path instead
Re-installation failed due to different application signatures.
ROM修改
NDK工具之 addr2line
NDK和Eclipse的集成
MySQL相关
ListView无法在onCreate的时候getChildCount()
JNI运用
Database Design/UUID vs Integer Auto-Increment
Android点滴积累
Android查看内存
Android.mk文件详解
Android string
Android NDK 官方下载地址
Adding ActionBar Items From Within Your Fragments
Activity 生命周期
gradle
_
back-end 11
cocos2dx 22
cocos2d-x3.x文字模糊
SSL
ClippingNode
sprite的触摸事件
cocos2dx内存管理
cocos2d-js
cocos2d-js安装
CCActionInterval
cocos bugs
不能在非主线程中使用OpenGL ES的UI函数
Menu
plist文件标识png图集的位置信息
锚点anchorPoint
详解Cocos2d-X中宏CC_DLL
编译注意点
点滴积累
windows搭建android和cocos2dx环境
sprite::create("*.png")崩溃
Unknown EABI object attribute 44
CCUserDefault使用注意点
APP_STL := gnustl_static APP_CPPFLAGS := -frtti APP_CPPFLAGS += -fexceptions
_
Unit php-fpm.service could not be found
Uncaught ReferenceError process is not defined
Uncaught ReferenceError Buffer is not defined
thread.cc Throwing new exception length=433 index=1340 ArrayIndexOutOfBoundsException
Provisioning profile doesn't include signing certificate
indenting spaces must be used in groups of 2
Nokogiri install failures
eth合约报错
xcode __nwlog_err_simulate_crash_libsystem
pod生成工程后编译lib
The SSL certificate is invalid
php编译错误
not a valid ELF
invalid resource directory name appcompat_v7 res crunch
Invalid Code Signing Entitlements
该文件没有与之关联的程序来执行该操作
dyld Library not loaded rpathlibfmodL
a2003- cant connect to MYSQL server on localhost
android.view.WindowManager BadTokenException is your activity running
android.view.WindowLeaked
no suitable device found no device found for connection
git push Server error goroutine 1
efrror RPC failed result=18 HTTP code 200
This version of the rendering library is more recent than your
err 1005 Can't create table error 150
could not initialize proxy no Session
could not execute query nested exception
ArtifactDescriptorException Failed to read artifact descriptor
is not a valid JNI reference
INSTALL_FAILED_DEXOPT
brut.androlib.AndrolibException ARSCDecoder.decode error
未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0”提供程序
无法解析 __imp__printf
无法定位程序输入点sdl_strlcpy
LNK1123: 转换到 COFF 期间失败: 文件无效或损坏
lwebsockets is not an object file
Failed to git submodule update --recursive --init
libpng error CgBI unhandled critical chunk
symbol not found for architecture armv7
provider: 共享内存提供程序, error: 0 管道的另一端上无任何进程 and sa登陆失败 错误:18456
file is universal 3 slices but does not contain an armv7s slice
HRESULT 0x80004005 E_FAIL
error 126
无法解析的外部符号:error LNK2019
无法解析的外部符号 RegQueryValueEx、RegCloseKey、RegOpenKeyEx、RegSetValueEx...
无法解析外部符号 __imp__CoUninitialize@0、_TID_D3DRMFrameTransformMatrix
无法解析_c_dfDIMouse、_c_dfDIKeyboard、_DirectInput8Create@20、_c_dfDIJoystick2
无法解析 __imp__ExtractIconW@12、 __imp__ExtractIconW@12
无法打开文件"dxerr9.lib"
无法打开文件 d3dx9.lib
无法启动应用程序
1>------ 已启动生成: 项目: Init Direct3D, 配置: D
1>------ 已启动生成/项目/Font, 配置/Debug Win3
安装DirectXSDK时提示Error Code s1023
不允许使用不完整的类型
warning:DIRECTINPUT_VERSION undefined. Defaulting to version 0x0800
warning MSB8004: Output 目录未以斜杠结尾。此生成实例将添
warning C4996: 'strcpy': This function or variable may be unsafe.
warning C4355: “this”: 用于基成员初始值设定项列表
warning C4290: 忽略 C++ 异常规范,但指示函数不是 __declspec(nothrow)
warning C4003: “max”宏的实参不足
vs2010出现link2005
static_cast(pStr)
release版本下静态链接库无法解析外部符号
pragma warning(disable:4996)
gult32.dll
gorm查询sqlite3报错
general error c101008a_ Failed to save the updated manifest to the
ft2build.h file not found with include, use “quotes” instead
error X3025
error LNK2019 __imp__InitCommonControls@0
error LNK2001 无法解析的外部符号_mainCRTStartup
error C2443: 操作数大小冲突
crosses initialization
cmath(19): error C2061: 语法错误: 标识符“acosf”
ava.io.IOException Cannot run program jarsigner.exe
__imp__InitCommonControlsEx@4 __imp__EndDialog
__gmsl:512:*** non-numeric second argument to `wordlist' function: ''.
_ITERATOR_DEBUG_LEVEL”的不匹配项问题
_ITERATOR_DEBUG_LEVEL
XCode: duplicate symbol error when using global variable - Stack Overflow
Application does not specify an API level requirement!
VS2010 fatal error C1902: 程序数据库管理器不匹配;请检查安装
S1023 error on installing DirectX SDK
LNK4006 symbol already defined in object; second definition ignored
LNK2001 : unresolved externals
IDirectSound8无法使用
Failure Reason Message from debugger Terminated due to memory issue
DirectX Preview window: WARNING: Pixel shader 'Pixel Shader' cannot be created on hardware rendering
COMMON ERROR - python
无法解析的外部符号 __imp__ExtractIconW@12
_
lua 9
unity3d 32
Unity 团结
Unity UIWidgets
Open Source for Unity
Unity超链接
Unity spine
Unity shader
Bloom
Particle System
Sprite Renderer
Overdraw
字体描边
Unity热门插件
Bmfont
TextMeshPro
UGUI优化
Unity DOTS
Unity大规模角色渲染
Unity热更方案
Unity 升级
Unity插件
Unity调用webservice
Unity调用C++的dll
Unity Error Solutions
Unity点滴积累
Unity NGUI
_
Unity 模型
Unity 优化
Unity Webview
Unity Odin
Unity Editor
HybridCLR
algorithm 86
Behaviour Tree
Hexagonal Grids
背包问题
域名
ipa重新打包
苹果过审
cocos2dx ipv6支持
redis
加密算法
protobuf
生成唯一id
文件读取效率研究
随机选项和宽字符输出
过桥最短时间
输入一个正整数
设计一个程序
表达式求值
罗马数字与整数相互转换
编程求两个矩形的相交矩形
给定一个字串X
砝码称重
母函数问题
模拟实现乘法运算
某人有三个儿子
有一个长度为N的数字串
有5座不同颜色的房子
最长子串
最大子矩阵之和
在字符串S中寻找最
写一个程序
写一个函数
二维数组排序
一个线段随机分成三段能够构成三角形的概率
一个int数组,里面数据无任何限制,要求求出所有这样的数a[i], 其左边的数都小于等于它,右边的数都大于等于它。 能否只用一个额外数组和少量其它空间实现。
How many 0 appears
Fabonacci数列定义为
Do remember
骆驼吃香蕉问题
错排原理
逻辑推理宴会握手
输入一个整数n
设计一个系统处理词语搭配问题
设计一个不能被继承的
设七位数是
编写代码把16进制表示的串转换为3进制表示的串
每个飞机只有一个油箱
概率问题
桌面上有24张光滑面扑克牌
根据上排给出十个数
有一个长度为998的数组
有一个复杂链表
有81个选手
有5个人比赛
有2.5亿个整数存放在一个文件中
有10个文件
无限容量的体育馆
数列L中有n个整数
把一个钝角三角形
循环队列
外星人打算将地球用来种蘑菇
在一天的24小时之中
判断另一字符串的所有字母是否在母串中都有
判断一个数是4的整数次幂
全部有火柴根组成
你有一个横6竖6的方格
九宫图解法
两个数组
不能使用库函数
下一个数是什么
一道小学数学题可以证明你是否可以玩股票
一个猜测游戏中
一个文件
一个教授逻辑学的教授
\[约瑟夫环\]n个数字
Longest Common Subsequence
Fibonacci
12个高矮不同的人
100层楼
1000瓶药水
0-1背包
正则表达式
随机洗牌:哪种算法正确
求连续自然数平方和的公式
各种算法复杂度比较
教你如何迅速秒杀掉:99%的海量数据处理面试题
_
game-engine 57
exr
xLua
Paper2D
rapidjson
unreal源码赏析
NEON
PainTown编译
scripting language
low level graphics library
格斗引擎
ios性能测试
UI Engines
Game Engines Comparison
g3log
Open Source Log Systems Comparison
View Frustum Culling
Matrix Layouts, DirectX and OpenGL
DirectX基础知识
Physics Engines
透视投影变换
编译ogre_src_v1-7-4 windows
编译 ogre 1.9.0 ios undo
绘制次序
纹理寻址模式设置不当
显存带宽 bandwidth
分析碰撞检测库Opcode
《Fighting, Antiquity》遇见的各种问题
send TEXCOORD from DirectX9.0 to HLSL
mul(inPos, matViewProjection) and mul(matViewProjection, inPos)
A* Pathfinding
X File Hierarchy Loading
VS高亮HLSL关键字
Umbra 3:次世代的遮挡裁剪
Steering Behaviors For Autonomous Charac
Rendering the Great Outdoors/Fast Occlusion Culling for Outdoor Environments
Programming OpenGL ES with ios
Perlin Noise
OpenGL中freeglut的安装
OpenGL
OpenGL ES hardware support
OgreSDK_vc10_v1-7-4第一次编译程序运行crash
Missing texture object named 'Texture0' in pixel shader 'Pixel Shader' in pass 'Pass 1'
Loading .x files the easy way
Load .obj model
Get Texture Coordinates from DirectX in Vertex Shader
Fx Composer
Effect Framework
DirectX 9.0中BeginPass和EndPass放置问题
DirectInput
Coding in RenderMonkey
Bézier curve
Bullet
Advanced Collision Detection Techniques
3D游戏引擎中的室外大场景渲染技术研究与实现
3D实时渲染中的BSP树和多边形剔除
fxc的使用及调试技巧
OGRE点滴积累
java 59
java基础知识
andriod源码编译
aar转jar
JAR creation failed. See details for additional information
获取焦点
某些android系统下自动优化代码
异常处理
内存泄露分析
代码混淆
enum
MultiValueMap
eclipse的devices上不显示调试程序包名
获取版本号和版本名
js语法
meta-data的获取
smali语法
mobile devices information
android 国际化语言 locale缩写
android error solutions
游戏崩溃查找dump crash堆栈信息
未签名的apk无法安装到手机上
延迟执行任务
平台接入
安装apk到手机中,elipse并非完全拷贝整个apk
多线程用多少个线程最合适
使用NDK编译so动态库
中国移动第三方接入
onNewIntent
eclipse调试android程序
eclipse下android环境搭建
apk重启程序代码
apk 签名
ant 自动编译
android开发中遇到sqlite3 not found
android制作九宫格图
android.database.CursorIndexOutOfBoundsException
android 指定类
android ndk 开发之Application.mk
android assets常见问题
android 4.0 NetworkOnMainThreadException
ZXing竖屏解决(完美版)
XP环境下java环境变量配置
Unable to execute dex/Multiple dex files define
The nested fileset element is deprectated, use a nested path instead
Re-installation failed due to different application signatures.
ROM修改
NDK工具之 addr2line
NDK和Eclipse的集成
MySQL相关
ListView无法在onCreate的时候getChildCount()
JNI运用
Database Design/UUID vs Integer Auto-Increment
Android点滴积累
Android查看内存
Android.mk文件详解
Android string
Android NDK 官方下载地址
Adding ActionBar Items From Within Your Fragments
Activity 生命周期
c++ 43
打印堆栈
switch case的效率问题
STL各容器操作
variadic templates
singleton class
POSIX
get class name based on class
#type 宏的含义
类模板的部分特化
各编译器对C++的支持度
#pragma once与 #ifndef的区别
#ifdef _DEBUG
重载识别多重继承
返回值尽量返回const值
缺省实参编译时刻决定
编译器优化
纯虚析构函数必须定义
类继承中调用函数
类模板运用之实现委托类
类模板运用
类模板的友元
类成员函数声明为另外一个类的友元
析构函数出域就析构
指针的运用
成员函数模板和自动转换的选择
成员函数指针的运用
成员函数和非成员函数重载问题
在if里面请写入语句 使得打印出 hello world。
typedef作用 —— 定义机器无关的类型
static_cast注意点
static DWORD成员变量定义
operator<<重载
multimap容器不能用greater_equal
case语句内定义变量
boost使用
本地函数定义是非法的
__attribute__
Type Conversion
Override controls override and final
OSI七层网络模型与TCP:IP四层网络模型
C:C++里面变量名的最大长度是多少?
C++模板初始化
.h和.hpp区别
mac 7
ios 12
game-design 15
eth 2
教你如何迅速秒杀掉:99%的海量数据处理面试题
2014年09月04日From: http://blog.csdn.net/v_july_v/article/details/7382693 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
前言 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
一般而言,标题含有“秒杀”,“99%”,“史上最全/最强”等词汇的往往都脱不了哗众取宠之嫌,但进一步来讲,如果读者读罢此文,却无任何收获,那么,我也甘愿背负这样的罪名,:-),同时,此文可以看做是对这篇文章:十道海量数据处理面试题与十个方法大总结的一般抽象性总结。
毕竟受文章和理论之限,本文将摒弃绝大部分的细节,只谈方法/模式论,且注重用最通俗最直白的语言阐述相关问题。最后,有一点必须强调的是,全文行文是基于面试题的分析基础之上的,具体实践过程中,还是得具体情况具体分析,且场景也远比本文所述的任何一种情况复杂得多。
OK,若有任何问题,欢迎随时不吝赐教。谢谢。
\
何谓海量数据处理? {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
所谓海量数据处理,无非就是基于海量数据上的存储、处理、操作。何谓海量,就是数据量太大,所以导致要么是无法在较短时间内迅速解决,要么是数据太大,导致无法一次性装入内存。
那解决办法呢?针对时间,我们可以采用巧妙的算法搭配合适的数据结构,如Bloom filter/Hash/bit-map/堆/数据库或倒排索引/trie树,针对空间,无非就一个办法:大而化小:分而治之/hash映射,你不是说规模太大嘛,那简单啊,就把规模大化为规模小的,各个击破不就完了嘛。
至于所谓的单机及集群问题,通俗点来讲,单机就是处理装载数据的机器有限(只要考虑cpu,内存,硬盘的数据交互),而集群,机器有多辆,适合分布式处理,并行计算(更多考虑节点和节点间的数据交互)。
再者,通过本blog内的有关海量数据处理的文章:[<span style="font-family:'Comic Sans MS';">Big Data Processing</span>](http://blog.csdn.net/v_july_v/article/category/1106578),我们已经大致知道,处理海量数据问题,无非就是:
\
- 分而治之/hash映射 + hash统计 + 堆/快速/归并排序;
- 双层桶划分
- Bloom filter/Bitmap;
- Trie树/数据库/倒排索引;
- 外排序;
-
分布式处理之Hadoop/Mapreduce。
下面,本文第一部分、从set/map谈到hashtable/hash_map/hash_set,简要介绍下set/map/multiset/multimap,及hash_set/hash_map/hash_multiset/hash_multimap之区别(万丈高楼平地起,基础最重要),而本文第二部分,则针对上述那6种方法模式结合对应的海量数据处理面试题分别具体阐述。
\
第一部分、从set/map谈到hashtable/hash_map/hash_set {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
稍后本文第二部分中将多次提到hash_map/hash_set,下面稍稍介绍下这些容器,以作为基础准备。一般来说,STL容器分两种,
- 序列式容器(vector/list/deque/stack/queue/heap),
- 关联式容器。关联式容器又分为set(集合)和map(映射表)两大类,以及这两大类的衍生体multiset(多键集合)和multimap(多键映射表),这些容器均以RB-tree完成。此外,还有第3类关联式容器,如hashtable(散列表),以及以hashtable为底层机制完成的hash_set(散列集合)/hash_map(散列映射表)/hash_multiset(散列多键集合)/hash_multimap(散列多键映射表)。也就是说,set/map/multiset/multimap都内含一个RB-tree,而hash_set/hash_map/hash_multiset/hash_multimap都内含一个hashtable。
所谓关联式容器,类似关联式数据库,每笔数据或每个元素都有一个键值(key)和一个实值(value),即所谓的Key-Value(键-值对)。当元素被插入到关联式容器中时,容器内部结构(RB-tree/hashtable)便依照其键值大小,以某种特定规则将这个元素放置于适当位置。
包括在非关联式数据库中,比如,在<span style="font-family:'Comic Sans MS';">MongoDB内</span>,文档(document)是最基本的数据组织形式,每个文档也是以Key-Value(键-值对)的方式组织起来。一个文档可以有多个Key-Value组合,每个Value可以是不同的类型,比如String、Integer、List等等。 \ <span style="white-space:pre;"></span><span style="font-family:'Comic Sans MS';">{ "name" : "July", \ <span class="Apple-converted-space"> </span><span style="white-space:pre;"></span>"sex" : "male", \
<span style="white-space:pre;"> </span>"age" : 23 } </span>
\
set/map/multiset/multimap
set,同map一样,所有元素都会根据元素的键值自动被排序,因为set/map两者的所有各种操作,都只是转而调用RB-tree的操作行为,不过,值得注意的是,两者都不允许两个元素有相同的键值。\
不同的是:set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值,而map的所有元素都是pair,同时拥有实值(value)和键值(key),pair的第一个元素被视为键值,第二个元素被视为实值。\
至于multiset/multimap,他们的特性及用法和set/map完全相同,唯一的差别就在于它们允许键值重复,即所有的插入操作基于RB-tree的insert_equal()而非insert_unique()。
hash_set/hash_map/hash_multiset/hash_multimap
hash_set/hash_map,两者的一切操作都是基于hashtable之上。不同的是,hash_set同set一样,同时拥有实值和键值,且实质就是键值,键值就是实值,而hash_map同map一样,每一个元素同时拥有一个实值(value)和一个键值(key),所以其使用方式,和上面的map基本相同。但由于hash_set/hash_map都是基于hashtable之上,所以不具备自动排序功能。为什么?因为hashtable没有自动排序功能。\
至于hash_multiset/hash_multimap的特性与上面的multiset/multimap完全相同,唯一的差别就是它们hash_multiset/hash_multimap的底层实现机制是hashtable(而multiset/multimap,上面说了,底层实现机制是RB-tree),所以它们的元素都不会被自动排序,不过也都允许键值重复。
所以,综上,说白了,什么样的结构决定其什么样的性质,因为<span style="font-family:Arial;">set/map/multiset/multimap都是基于RB-tree</span><span style="font-family:Arial;">之上,所以有自动排序功能,而h</span><span style="font-family:Arial;">ash\_set/hash\_map/hash\_multiset/hash\_multimap都是基于hashtable之上,所以不含有自动排序功能,至于加个前缀multi\_无非就是允许键值重复而已</span>。
此外,
- 关于什么hash,请看blog内此篇文章:http://blog.csdn.net/v_JULY_v/article/details/6256463;
- 关于红黑树,请参看blog内系列文章:http://blog.csdn.net/v_july_v/article/category/774945,
-
关于hash_map的具体应用:http://blog.csdn.net/sdhongjun/article/details/4517325,关于hash_set:http://blog.csdn.net/morewindows/article/details/7330323。
OK,接下来,请看本文第二部分、处理海量数据问题之六把密匙。
\
第二部分、处理海量数据问题之六把密匙 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
密匙一、分而治之/Hash映射 + Hash统计 + 堆/快速/归并排序 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
**1、海量日志数据,提取出某日访问百度次数最多的那个IP。**\
既然是海量数据处理,那么可想而知,给我们的数据那就一定是海量的。针对这个数据的海量,我们如何着手呢?对的,无非就是分而治之/hash映射 +
hash统计 + 堆/快速/归并排序,说白了,就是先映射,而后统计,最后排序:
1. 分而治之/hash映射:针对数据太大,内存受限,只能是:把大文件化成(取模映射)小文件,即16字方针:大而化小,各个击破,缩小规模,逐个解决
2. hash统计:当大文件转化了小文件,那么我们便可以采用常规的hash\_map(ip,value)来进行频率统计。
3. 堆/快速排序:统计完了之后,便进行排序(可采取堆排序),得到次数最多的IP。
具体而论,则是: “首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2\^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。”–十道海量数据处理面试题与十个方法大总结。
关于本题,还有几个问题,如下:
1、Hash取模是一种等价映射,不会存在同一个元素分散到不同小文件中去的情况,即这里采用的是mod1000算法,那么相同的IP在hash后,只可能落在同一个文件中,不可能被分散的。\
2、那到底什么是hash映射呢?简单来说,就是为了便于计算机在有限的内存中处理big数据,从而通过一种映射散列的方式让数据均匀分布在对应的内存位置(如大数据通过取余的方式映射成小树存放在内存中,或大文件映射成多个小文件),而这个映射散列方式便是我们通常所说的hash函数,设计的好的hash函数能让数据均匀分布而减少冲突。尽管数据映射到了另外一些不同的位置,但数据还是原来的数据,只是代替和表示这些原始数据的形式发生了变化而已。
此外,有一朋友<span style="font-size:16px;">quicktest</span>用python语言实践测试了下本题,地址如下:[<span style="font-family:'Comic Sans MS';">http://blog.csdn.net/quicktest/article/details/7453189</span>](http://blog.csdn.net/quicktest/article/details/7453189)。谢谢。OK,有兴趣的,还可以再了解下<span style="font-size:12px;">一致性hash算法</span>,见blog内此文第五部分:[<span style="font-family:'Comic Sans MS';">http://blog.csdn.net/v\_july\_v/article/details/6879101</span>](http://blog.csdn.net/v_july_v/article/details/6879101)。
2、寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
// 300W个,大概7亿B,1G≈10亿B,可以装进.
由上面第1题,我们知道,数据大则划为小的,但如果数据规模比较小,能一次性装入内存呢?比如这第2题,虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去,而现在只是需要一个合适的数据结构,在这里,Hash Table绝对是我们优先的选择。所以我们放弃分而治之/hash映射的步骤,直接上hash统计,然后排序。So,
- hash统计:先对这批海量数据预处理(维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内用Hash表完成了统计;
-
堆排序:第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N为1000万,N’为300万)。
别忘了这篇文章中所述的堆排序思路:“维护k个元素的最小堆,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>…kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(用时logk),否则不更新堆。这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk。”–第三章续、Top K算法问题的实现。\
当然,你也可以采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小堆来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
由上面那两个例题,分而治之 + hash统计 +
堆/快速排序这个套路,我们已经开始有了屡试不爽的感觉。下面,再拿几道再多多验证下。请看此第3题:又是文件很大,又是内存受限,咋办?还能怎么办呢?无非还是:
- 分而治之/hash映射:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
- hash统计:对每个小文件,采用trie树/hash_map等统计每个文件中出现的词以及相应的频率。
- 堆/归并排序:取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。最后就是把这5000个文件进行归并(类似于归并排序)的过程了。
**4、海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。**
此题与上面第3题类似,
1. 堆排序:在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大。
2. 求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据,再利用上面类似的方法求出TOP10就可以了。
上述第4题的此解法,经读者反应有问题,如举个例子如求2个文件中的top2,照上述算法,如果第一个文件里有:a 49次b 50次c 2次d 1次第二个文件里有:a 9次b 1次c 11次d 10次虽然第一个文件里出来top2是b(50次),a(49次),第二个文件里出来top2是c(11次),d(10次),然后2个top2:b(50次)a(49次)与c(11次)d(10次)归并,则算出所有的文件的top2是b(50 次),a(49 次),但实际上是a(58 次),b(51 次)。是否真是如此呢?若真如此,那作何解决呢?正如老梦所述:首先,先把所有的数据遍历一遍做一次hash(保证相同的数据条目划分到同一台电脑上进行运算),然后根据hash结果重新分布到100台电脑中,接下来的算法按照之前的即可。最后由于a可能出现在不同的电脑,各有一定的次数,再对每个相同条目进行求和(由于上一步骤中hash之后,也方便每台电脑只需要对自己分到的条目内进行求和,不涉及到别的电脑,规模缩小)。
**5、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。**\
直接上:
- hash映射:顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
- hash统计:找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。注:hash_map(query,query_count)是用来统计每个query的出现次数,不是存储他们的值,出现一次,则count+1。
- 堆/快速/归并排序:利用快速/堆/归并排序按照出现次数进行排序,将排序好的query和对应的query_cout输出到文件中,这样得到了10个排好序的文件(记为
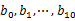 )。最后,对这10个文件进行归并排序(内排序与外排序相结合)。
)。最后,对这10个文件进行归并排序(内排序与外排序相结合)。
除此之外,此题还有以下两个方法:
方案2:一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。\
方案3:与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
6、 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 分而治之/hash映射:遍历文件a,对每个url求取
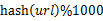 ,然后根据所取得的值将url分别存储到1000个小文件(记为
,然后根据所取得的值将url分别存储到1000个小文件(记为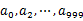 )中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为
)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为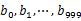 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件(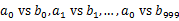 )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 -
hash统计:求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
OK,此第一种方法:分而治之/hash映射 + hash统计 + 堆/快速/归并排序,再看最后4道题,如下:
7、怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
8、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。
9、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。
\
** 10. 1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?**
\
- 方案1:这题用trie树比较合适,hash_map也行。
- 方案2:from xjbzju:,1000w的数据规模插入操作完全不现实,以前试过在stl下100w元素插入set中已经慢得不能忍受,觉得基于hash的实现不会比红黑树好太多,使用vector+sort+unique都要可行许多,建议还是先hash成小文件分开处理再综合。
上述方案2中读者xbzju的方法让我想到了一些问题,即是set/map,与hash\_set/hash\_map的性能比较?共计3个问题,如下:
- 1、hash\_set在千万级数据下,insert操作优于set?
这位blog:<http://t.cn/zOibP7t> 给的实践数据可靠不?
- 2、那map和hash\_map的性能比较呢?
谁做过相关实验?
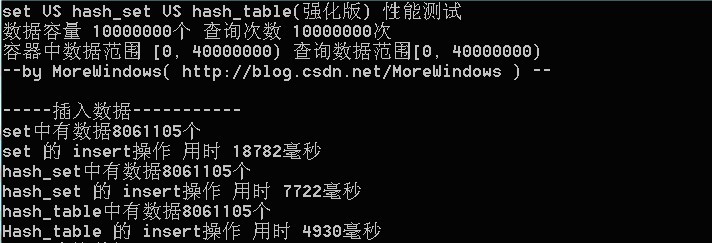
\
\
- 3、那查询操作呢,如下段文字所述?
\

或者小数据量时用map,构造快,大数据量时用hash\_map?
rbtree PK hashtable
据朋友№邦卡猫№的做的红黑树和hash table的性能测试中发现:当数据量基本上int型key时,hash table是rbtree的3-4倍,但hash table一般会浪费大概一半内存。
因为hash table所做的运算就是个%,而rbtree要比较很多,比如rbtree要看value的数据 ,每个节点要多出3个指针(或者偏移量) 如果需要其他功能,比如,统计某个范围内的key的数量,就需要加一个计数成员。
且1s rbtree能进行大概50w+次插入,hash table大概是差不多200w次。不过很多的时候,其速度可以忍了,例如倒排索引差不多也是这个速度,而且单线程,且倒排表的拉链长度不会太大。正因为基于树的实现其实不比hashtable慢到哪里去,所以数据库的索引一般都是用的B/B+树,而且B+树还对磁盘友好(B树能有效降低它的高度,所以减少磁盘交互次数)。比如现在非常流行的NoSQL数据库,像MongoDB也是采用的B树索引。关于B树系列,请参考本blog内此篇文章:[从B树、B+树、B\*树谈到R
树](http://blog.csdn.net/v_JULY_v/archive/2011/06/07/6530142.aspx)。
\
OK,更多请待后续实验论证。接下来,咱们来看第二种方法,双层捅划分。
\
密匙二、双层桶划分 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
\
双层桶划分—-其实本质上还是分而治之的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字\
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
11、2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。\
有点像鸽巢原理,整数个数为2\^32,也就是,我们可以将这2\^32个数,划分为2\^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
12、5亿个int找它们的中位数。\
这个例子比上面那个更明显。首先我们将int划分为2\^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。\
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。即可以先将int64分成2\^24个区域,然后确定区域的第几大数,在将该区域分成2\^20个子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2\^20,就可以直接利用direct addr table进行统计了。
\
密匙三:Bloom filter/Bitmap {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
Bloom filter {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;font-size:14px;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
关于什么是Bloom filter,请参看blog内此文:
\
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是
counting Bloom
filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge
大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom
filter内存上通常都是节省的。
扩展:
Bloom
filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting
bloom
filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral
Bloom
Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
\
13、给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2\^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。
同时,上文的第5题:给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
Bitmap {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;font-size:14px;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
\
- 关于什么是Bitmap,请看blog内此文第二部分:http://blog.csdn.net/v_july_v/article/details/6685962。
\
下面关于Bitmap的应用,直接上题,如下第9、10道:
14、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2\^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。\
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
15、腾讯面试题:给40亿个不重复的unsigned
int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
方案1:frome
oo,用位图/Bitmap的方法,申请512M的内存,一个bit位代表一个unsigned
int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
密匙四、Trie树/数据库/倒排索引 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
Trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
- 上面的第2题:寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。\
- 上面的第5题:有10个文件,每个文件1G,每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序。
- 1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
- 上面的第8题:一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词。其解决方法是:用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度),然后是找出出现最频繁的前10个词。
\
更多有关Trie树的介绍,请参见此文:<span style="line-height:26px;color:#333333;font-size:14px;">[<span style="font-family:SimHei;">从Trie树(字典树)谈到后缀树</span>](http://blog.csdn.net/v_july_v/article/details/6897097)<span style="font-family:Arial;">。</span></span>
数据库索引
适用范围:大数据量的增删改查\
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
- 关于数据库索引及其优化,更多可参见此文:http://www.cnblogs.com/pkuoliver/archive/2011/08/17/mass-data-topic-7-index-and-optimize.html;
- 关于MySQL索引背后的数据结构及算法原理,这里还有一篇很好的文章:http://www.codinglabs.org/html/theory-of-mysql-index.html;
- 关于B 树、B+ 树、B* 树及R 树,本blog内有篇绝佳文章:http://blog.csdn.net/v_JULY_v/article/details/6530142。
倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询\
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = “it is what it is”
T1 = “what is it”
T2 = “it is a banana”
我们就能得到下面的反向文件索引:
“a”: {2}
“banana”: {2}
“is”: {0, 1, 2}
“it”: {0, 1, 2}
“what”: {0, 1}
检索的条件”what”,”is”和”it”将对应集合的交集。
\
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:\
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
关于倒排索引的应用,更多请参见:
\
密匙五、外排序 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
适用范围:大数据的排序,去重\ 基本原理及要点:外排序的归并方法,置换选择败者树原理,最优归并树\ 扩展:\ 问题实例:\
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。\
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1M做hash明显不够,所以可以用来排序。内存可以当输入缓冲区使用。</span></span>
关于多路归并算法及外排序的具体应用场景,请参见blog内此文:
\
密匙六、分布式处理之Mapreduce {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。但如果你要我再通俗点介绍,那么,说白了,Mapreduce的原理就是一个归并排序。
适用范围:数据量大,但是数据种类小可以放入内存\ 基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。\ 扩展:\ 问题实例:\
- The canonical example application of MapReduce is a process to count the appearances of each different word in a set of documents:
- 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
- 一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N\^2个数的中数(median)?
\
更多具体阐述请参见blog内:
其它模式/方法论,结合操作系统知识 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
至此,六种处理海量数据问题的模式/方法已经阐述完毕。据观察,这方面的面试题无外乎以上一种或其变形,然题目为何取为是:秒杀99%的海量数据处理面试题,而不是100%呢。OK,给读者看最后一道题,如下:
非常大的文件,装不进内存。每行一个int类型数据,现在要你随机取100个数。\
我们发现上述这道题,无论是以上任何一种模式/方法都不好做,那有什么好的别的方法呢?我们可以看看:操作系统内存分页系统设计(说白了,就是映射+建索引)。
Windows
2000使用基于分页机制的虚拟内存。每个进程有4GB的虚拟地址空间。基于分页机制,这4GB地址空间的一些部分被映射了物理内存,一些部分映射硬盘上的交换文
件,一些部分什么也没有映射。程序中使用的都是4GB地址空间中的虚拟地址。而访问物理内存,需要使用物理地址。
关于什么是物理地址和虚拟地址,请看:\
- 物理地址 (physical address):
放在寻址总线上的地址。放在寻址总线上,如果是读,电路根据这个地址每位的值就将相应地址的物理内存中的数据放到数据总线中传输。如果是写,电路根据这个
地址每位的值就将相应地址的物理内存中放入数据总线上的内容。物理内存是以字节(8位)为单位编址的。
- 虚拟地址 (virtual address):
4G虚拟地址空间中的地址,程序中使用的都是虚拟地址。 使用了分页机制之后,4G的地址空间被分成了固定大小的页,每一页或者被映射到物理内存,或者被映射到硬盘上的交换文件中,或者没有映射任何东西。对于一
般程序来说,4G的地址空间,只有一小部分映射了物理内存,大片大片的部分是没有映射任何东西。物理内存也被分页,来映射地址空间。对于32bit的
Win2k,页的大小是4K字节。CPU用来把虚拟地址转换成物理地址的信息存放在叫做页目录和页表的结构里。
物理内存分页,一个物理页的大小为4K字节,第0个物理页从物理地址
0x00000000
处开始。由于页的大小为4KB,就是0x1000字节,所以第1页从物理地址
0x00001000 处开始。第2页从物理地址 0x00002000
处开始。可以看到由于页的大小是4KB,所以只需要32bit的地址中高20bit来寻址物理页。 \
返回上面我们的题目:非常大的文件,装不进内存。每行一个int类型数据,现在要你随机取100个数。针对此题,我们可以借鉴上述操作系统中内存分页的设计方法,做出如下解决方案:
操作系统中的方法,先生成4G的地址表,在把这个表划分为小的4M的小文件做个索引,二级索引。30位前十位表示第几个4M文件,后20位表示在这个4M文件的第几个,等等,基于key value来设计存储,用key来建索引。
但如果现在只有10000个数,然后怎么去随机从这一万个数里面随机取100个数?请读者思考。
参考文献 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
- 十道海量数据处理面试题与十个方法大总结;
- 海量数据处理面试题集锦与Bit-map详解;
- 十一、从头到尾彻底解析Hash表算法;
- 海量数据处理之Bloom Filter详解;
- 从Trie树(字典树)谈到后缀树;
- 第三章续、Top K算法问题的实现;
- 第十章、如何给10\^7个数据量的磁盘文件排序;
- 从B树、B+树、B*树谈到R 树;
- 第二十三、四章:杨氏矩阵查找,倒排索引关键词Hash不重复编码实践;
- 第二十六章:基于给定的文档生成倒排索引的编码与实践;
- 从Hadhoop框架与MapReduce模式中谈海量数据处理;
- 第十六~第二十章:全排列,跳台阶,奇偶排序,第一个只出现一次等问题;
- http://blog.csdn.net/v_JULY_v/article/category/774945;
- STL源码剖析第五章,侯捷著;
- 2012百度实习生招聘笔试题:http://blog.csdn.net/hackbuteer1/article/details/7542774。
后记 {style=”text-align:left;padding-bottom:0px;line-height:26px;widows:2;text-transform:none;background-color:#ffffff;font-variant:normal;font-style:normal;text-indent:0px;margin:0px;padding-left:0px;padding-right:0px;font-family:Arial;white-space:normal;orphans:2;letter-spacing:normal;color:#333333;word-spacing:0px;padding-top:0px;-webkit-text-size-adjust:auto;-webkit-text-stroke-width:0px;”}
经过上面这么多海量数据处理面试题的轰炸,我们依然可以看出这类问题是有一定的解决方案/模式的,所以,不必将其神化。然这类面试题所包含的问题还是比较简单的,若您在这方面有更多实践经验,欢迎随时来信与我不吝分享:zhoulei0907@yahoo.cn。当然,自会注明分享者及来源。
不过,相信你也早就意识到,若单纯论海量数据处理面试题,本blog内的有关海量数据处理面试题的文章已涵盖了你能在网上所找到的70\~80%。但有点,必须负责任的敬告大家:无论是这些海量数据处理面试题也好,还是算法也好,面试时,70\~80%的人不是倒在这两方面,而是倒在基础之上(诸如语言,数据库,操作系统,网络协议等等),所以,无论任何时候,基础最重要,没了基础,便什么都不是。如果你问我什么叫做掌握了基础,很简单,我可以举个例子,如到这里:[http://forum.csdn.net/BList/Cpp/](http://forum.csdn.net/BList/Cpp/),如果你几乎能解决那里的全部问题,那么你的c/c++基础便够了。
最后,推荐国外一面试题网站:<http://www.careercup.com/>,以及个人正在读的Redis/MongoDB绝佳站点:<http://blog.nosqlfan.com/>。
OK,本文若有任何问题,欢迎随时不吝留言,评论,赐教,谢谢。完。